

... oder wie wir uns beinahe aus unseren Managed Servern ausgesperrt haben
Donnerstag, der 19. März 2020 beginnt als “ganz normaler” Tag im Home-Office. Das ganze Team bei nine arbeitet seit Beginn der Woche von zu Hause und hat sich mittlerweile einigermassen auf die neue Situation eingestellt. Wir nutzen Slack oder Hangouts für unsere Daily Stand-Ups oder Meeting Video Calls und diskutieren auf Slack darüber was das stabilere System ist.
11:00 Wir realisieren, dass wir ein Problem haben - Ein Kunde von uns kann sich nicht via VPN verbinden und unser Monitoring alarmiert das einige Server down sind. Doch noch ist der genaue Umfang unbekannt - Handelt es sich um einen kleinen Ausfall oder eine Krise?
Fakt ist: wir müssen sofort reagieren! Es kommen immer mehr kritische Warnungen von den internen und externen Monitoring Systemen und einzelne Mitarbeitende melden über Slack, dass sie sich nicht mehr auf Server verbinden können oder ihre VPN Verbindungen werden nicht neu aufgebaut. Erste Analysen finden teamintern statt und es ist naheliegend, dass irgendwas mit dem Netzwerk oder vielleicht den DNS Resolvern nicht stimmt. Wir haben eine Krise!
11:20 Der officer of the day Tajno startet einen dedizierten Slack Channel. Stefan und Patrick vom Team IT / Managed Services übernehmen die Koordination in die Teams und Kyon vom Customer Service Desk (CSD) die Kommunikation nach aussen.
Natürlich haben unsere Kunden mittlerweile gemerkt, dass ihre Websites sowie das Mailsystem nicht mehr funktionieren und der CSD hat alle Hände voll zu tun deren Anfragen zu beantworten. Die Frage ist natürlich immer die gleiche: “Wie lange dauert es noch bis meine Website wieder erreichbar ist oder bis ich wieder wichtige E-Mails verschicken kann?” Das wissen wir auch nicht, denn wir tappen zu diesem Zeitpunkt genauso im Dunkeln. Mittlerweile wissen wir aber zumindest, dass nicht das Netzwerk das Problem ist. Selbst diese Erkenntnis fällt uns nicht leicht, da auch die Monitoring Systeme nicht erreichbar sind.
Wir merken aber schnell, dass es noch offene SSH Verbindungen auf unsere Server gibt und nur neue Verbindungen nicht mehr hergestellt werden können. Dass unsere DNS Resolver das Root Problem sind, glauben wir mittlerweile nicht mehr. Ja - sie funktionieren nicht mehr. Aber das ist nur ein weiteres Symptom, denn wir können uns selbst über eine direkte IP nicht mehr auf einige unserer Server verbinden:
Wir sind effektiv bei unseren eigenen Servern ausgesperrt!
12:10 Lukas fährt ins Datacenter, Team Managed Services - speziell André - wechselt in den Hacker Modus.
Ohne Zugriff auf die eigenen Server und ohne DNS sind wir effektiv aufgeschmissen. Jetzt gibt es zwei Optionen - physischer Zugriff auf den Server oder der Zugriff über ein Management System, das auch sonst verwendet wird, um nicht mehr bootende Server zu reparieren. André hat über ein Emergency System einen funktionierenden Management Server gefunden. Auf diesem nutzt er den Google DNS um die IP unseres Resolvers herausfinden:
dig nsr1.nine.ch @8.8.8.8
Mit der IP kann er sich per SSH verbinden. Success. Wir kommen näher an die Ursache des Problems.
Diesen Trick benutzen übrigens auch unsere Root Kunden. Sie bringen ihre Server selbst wieder online, indem sie von nine Resolvern auf andere funktionierende DNS Resolver wechseln.
Es zeigt sich schnell, dass die Firewall Regeln, welche sonst unerlaubten Zugriff auf das System verhindern, geändert wurden. Sie sind auf eine Default-Einstellung gesetzt, welche es nicht mal nine Mitarbeitenden erlaubt, sich vom Management System her anzumelden und nun plötzlich nach Passwörtern gefragt werden. Das gleiche Verhalten können wir auf anderen Servern beobachten. Die Regeln sind schnell manuell angepasst und das erste System funktioniert wieder. Das Problem ist nun: wir haben potenziell tausende betroffene Systeme.
12:35 André meldet via Slack, dass der erste Resolver wieder erreichbar ist. Die Task Force welche mittlerweile aus allen MS Team Mitgliedern besteht, beginnt die restlichen nine Systeme wiederherzustellen und koordiniert sich via Slack.
Da wir jetzt effektiv wieder unsere internen System mittels DNS erreichen, beginnen wir die Kundensysteme mit einem SLA wiederherzustellen. Doch dann passiert das Unerwartete!
Bereits “gefixte” Systeme funktionieren plötzlich wieder nicht mehr
Durchatmen - es gibt nur einen Grund, warum so etwas passieren kann. Wir deaktivieren unseren Puppet Loadbalancer. Systeme auf denen die Symptome wieder auftreten werden erneut gefixt, erneute Änderungen durch Puppet sind nun vorerst ausgeschlossen - Weitermachen.
Puppet ist unser Konfigurationsmanagement-System, welches sonst jeden Aspekt eines Servers managed - Software Installation, Security und Upgrades.
Warum tust du uns das an, Puppet? Ist es ein fehlerhafter Commit, der Puppet anweist diesen Change auszuführen? Josi gibt Entwarnung - Diese Ursache können wir anhand der Git History ausschliessen. Wir erinnern uns, dass auf unseren Servern im Rahmen unserer regulären Maintenance ein neues Puppet Paket installiert wurde. Es war ein Patch ohne funktionale Änderungen im Changelog. Die beobachteten Symptome passen unmöglich auf dieses Update. Trotzdem - die Ursache liegt nun ganz sicher bei Puppet.
13:15 Phil informiert unsere Kunden auf https://status.nine.ch, dass die Ursache gefunden ist und wir nun an einer Lösung arbeiten.
Daniel findet heraus, dass es ein Problem bei der Zuordnung der Nodes anhand der Zertifikate gibt. Puppet hat die entsprechenden Node Manifests "vergessen" und verwendet somit eine Default Konfiguration. Ausserdem hat Patrick in den Puppet Logs etwas von einem Certificate Error gelesen.

Ein erster Test mit einem FQDN anstelle des Hostnamen schafft Klarheit. Es muss damit zusammenhängen.
Parallel zu den Engineers, die im Eiltempo unsere Infrastruktur und Kundensysteme fixen, beginnt unser Code Spezialist Demian das Puppet Problem genauer zu analysieren. Puppet ist Open Source Software - Jede Änderungen von den Entwicklern ist im Programmcode nachvollziehbar.
Antonios schickt einen Link ins Slack:
https://nvd.nist.gov/vuln/detail/CVE-2020-7942#VulnChangeHistorySection,
Könnte dieser Change die Ursache sein? Schnell sind die Pakete von Puppet auf die vorherige Version wiederhergestellt (5.2.13 auf 5.2.12), aber das Problem ist nicht gefixt. Demian gräbt im Code von Puppet und findet einen Commit der seltsam aussieht: https://github.com/puppetlabs/puppet/commit/df826baa0ed1f3ebb182798aa6e04a9e8f35fd80#
(PUP-10238) Change default value of strict_hostname_checking to true
Previously our default value of strict_hostname_checking was false which allowed matching dotted segments of a nodes certname (its CN in its certificate) as well as the segments of its fqdn fact, or hostname + domain fact.

Weil der Loadbalancer für Puppet auf dem Puppet Master aus bekannten Gründen abgeschaltet ist, testen wir weiter, indem wir den Puppet Client statt auf den Master auf einen der anderen Server zugreifen lassen:
puppet agent --test --noop --server puppetslave.nine.ch
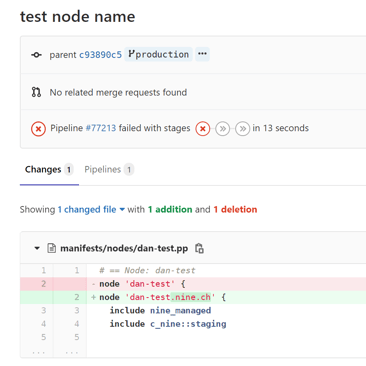
Damit haben wir endlich die Problemursache gefunden. Trotzdem können wir jetzt nicht auf die Schnelle alle Server Manifeste umbenennen! Wir brauchen das ursprüngliche Verhalten, bevor der Default geändert wurde. Zum Glück kann dies global auf dem Puppet Server definiert werden und damit den geänderten Default, der selbst vom Downgrade nicht zurückgesetzt wurde, permanent überschreiben.
15:28 Status Update - Alle Systeme die IPV4 verwenden sind wieder erreichbar.
Parallel zum Puppet Fix hat die restliche Task Force mittels eines Bash Scripts die IP Tables wiederhergestellt.
for i in $(list_managed_servers); do echo $i; ssh $i "cd /etc/iptables && git checkout @{yesterday} -- rules.v* && iptables-restore < /etc/iptables/rules.v4"; done
for i in $(list_managed_servers); do echo $i; ssh $i "cd /etc/iptables && ip6tables-restore < /etc/iptables/rules.v6”; done
16:30 Wir können erleichtert folgende Meldung machen: “All systems are now reachable again over IPv4 and IPv6.”
Noch bis in den Abend überprüfen die Managed Services Engineers alle Systeme und stellen Puppet letztendlich wieder an.
Nach 7:39:07h beendet Tajno den Slack Call.

Alles in Allem hatten wir Glück im Unglück. Dadurch, dass Puppet auch unsere DNS Resolver disabled hatte und ebenso seine eigenen Services mittels Firewall blockierte, konnte der Fehler nicht auf alle Systeme übergreifen.
Was haben wir daraus gelernt? Sehr viel! Bis heute sind bereits 14 Tickets mit Massnahmen entstanden, welche Optimierungen wir bei unseren Prozessen und im Engineering vorsehen. Dabei sind zum Beispiel ein Emergency Wiki und E-Mail oder Passwort-Tool müssen nicht nur an einem anderen Standort, sondern auch komplett unabhängig von der Domain nine.ch sein.
Aber auch Optimierungen in der Kundenkommunikation, wie auch Sicherheits- und Prozessverbesserungen rund um das Thema Puppet und Patching stehen im Fokus. Das Team Managed Services wird weitere Blogs dazu veröffentlichen.
Welche Erfahrungen habt Ihr mit euren Konfigurationsmanagement-Tools gemacht? Teilt eure Stories mit uns per Twitter, LinkedIn oder Youtube
Keinen Blogpost mehr verpassen?


