
Neue Trends in der IT entstehen heutzutage ja fast jeden Monat – und verschwinden meist auch so schnell wieder. Wir bei nine.ch versuchen immer Neuentwicklungen auf der Spur zu bleiben, um herauszufinden, ob wir durch sie einen Mehrwert für unsere Kunden erreichen können. Ein Technologie-Trend, welcher nun schon länger besteht, ist das Ausführen von Applikationen in Containern. Bekannt geworden ist die Containervirtualisierung durch ‘Docker’ (obwohl es das ja schon viel früher gab).
Wir wollten nun wissen inwieweit die Technologie für uns (und unsere Kunden) anwendbar ist. Dazu mussten wir erst einmal wissen, was wir erreichen wollen und für was unsere Kunden Containervirtualisierung benötigen. Also ab in die ‘Befragungs- und Analysephase’.
Zielfindung
Dabei entstanden folgende Ziele und Aussagen:
- Geschätzt wird die ‘Freiheit im Systembau’ welche Docker bietet.
- Das Deployment von Docker Containern unterscheidet sich nicht in den einzelnen Phasen der Applikationsentwicklung. Entwickler können das Docker Image selbst herstellen und es dann auf die gleiche Weise auf unterschiedlichen Servern starten.
- Manchmal sollen eigene Applikationen/Dienste als Benutzer ‘root’ laufen (was auf unseren Managed Servern so nicht möglich ist).
- Docker Container können schnell horizontal skaliert werden.
- Der Einsatz von Docker sollte nicht auf einen Server reduziert sein. Vielmehr soll Docker in Clustern eingesetzt werden.
- Sicherheit hat eine hohe Priorität.
Da Docker Container auch einen geringeren ‘Overhead’ als Voll- bzw. Paravirtualisierung besitzen, stand für uns der Aspekt eines ‘Multi-Tenant Docker Clusters’ im Vordergrund. Dadurch lassen sich Ressourcen optimal ausnutzen.
Sobald man Docker auf mehr als einem Server einsetzen will, empfiehlt sich der Einsatz eines Orchestrierungstools. Die populärsten Vertreter sind hierbei Docker Swarm, Fleet von CoreOS und Kubernetes. Wir haben uns dabei für Kubernetes entschieden. Das Konzept der Trennung der einzelnen Funktionalitäten in Komponenten, welche alle via API steuerbar sind, war dabei besonders interessant. Weiterhin fanden wir die Umsetzung/Abstrahierung des Netzwerks sehr spannend.
Wie funktioniert Kubernetes genau?
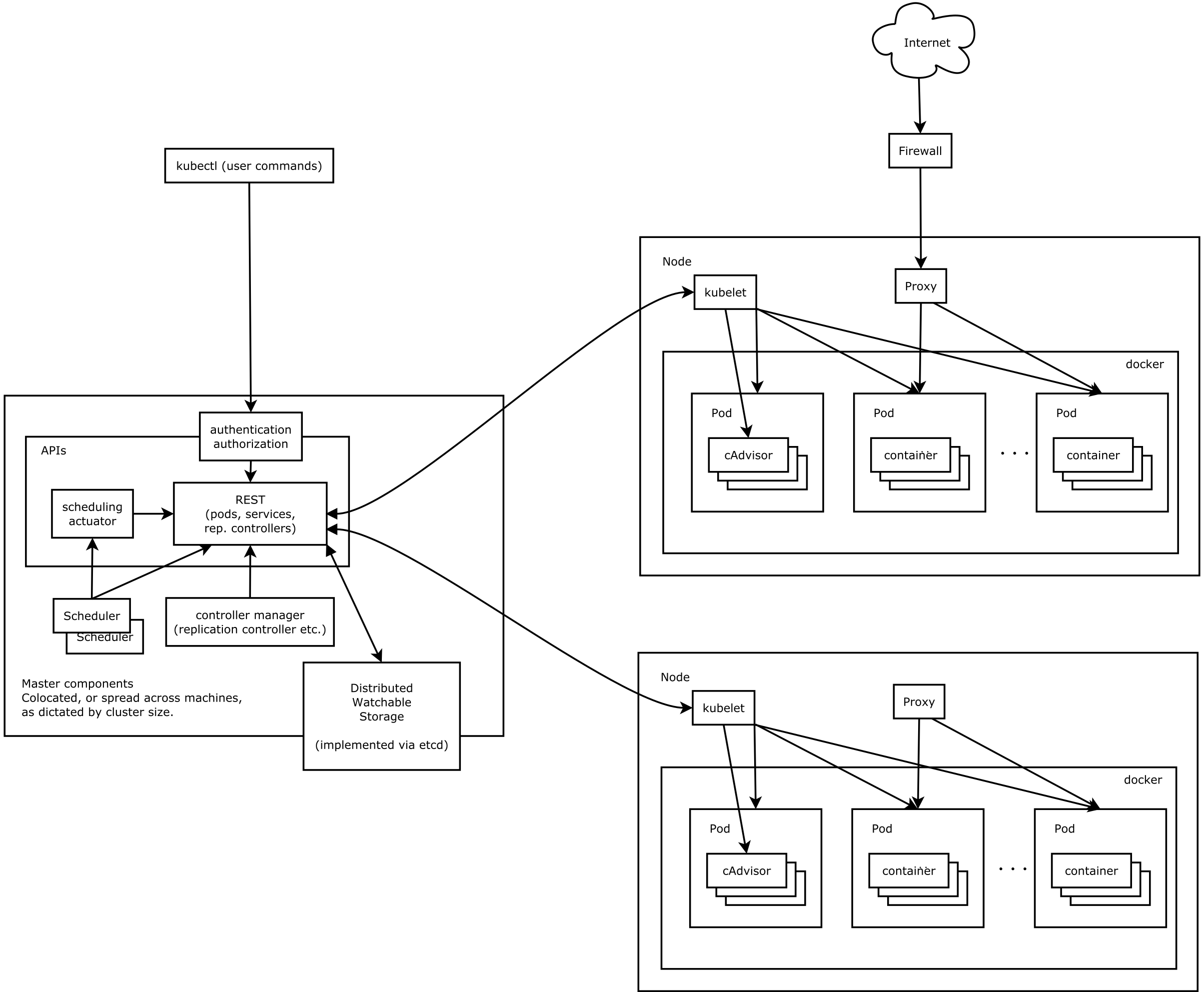
/kubernetes_architecture.png)
Wie bereits erwähnt, unterteilt Kubernetes die einzelnen Bestandteile eines ‘Container Clusters’ in verschiedene Komponenten. Jede dieser Komponenten ist dabei über eine REST API zugänglich. Es existiert ein Master Server auf welchem verschiedene Daemons laufen. Diese stellen Dienste wie die bereits genannte API, den Scheduler oder den Controller Manager bereit. Der Zustand des Clusters wird über REST API Aufrufe geändert. Zur Vereinfachung existiert das CLI Tool kubectl. Mit diesem lassen sich neue Container starten, Deployments durchführen oder auch PODs (siehe unten) horizontal skalieren. Um sich den Zustand einzelner Objekte zu merken, benötigt Kubernetes zusätzlich etcd.
Die Docker Container selbst laufen auf den sogenannten Nodes (oder Minions wie sie früher genannt wurden). Die Kommunikation zwischen Master Server und Node wird mit Hilfe des sogenannten kubelet Daemons durchgeführt. Dieser läuft auf jedem Node und reagiert auf die jeweiligen Befehle des Master Servers. Eine weitere Komponente welche auf jedem Node ausgeführt wird, ist der kube-proxy. Er ist für das Routing von Netzwerkanfragen zuständig.
Wichtige Komponenten von Kubernetes
Wie schon erwähnt besitzt Kubernetes ein eigenes Konzept hinsichtlich der Komponenten. Es kommen immer Weitere hinzu, aber die wichtigsten Bestandteile sollen kurz erklärt werden.
POD
Eine der wichtigsten Komponenten von Kubernetes ist der POD. In einem POD kann man eine oder mehrere ‘dockerisierte’ Anwendungen zusammenfassen. Dies macht besonders bei Applikationen Sinn welche man auch in einer konventionellen Virtualisierung bspw. auf dem selben KVM Host betrieben hat. Kubernetes betrachtet daher keine einzelnen Container, sondern immer PODs (natürlich kann man in einem POD auch nur einen Container ausführen, falls man das möchte). Docker Container in einem POD teilen sich verschiedene Linux Namespaces, darunter auch den Network Namespace. Die Anwendungen können daher über die ‘localhost’ Schnittstelle miteinander kommunizieren. Möchte man Volumes verwenden so kann man diese auch nur pro POD nutzen. Dabei erhält jeder Container des PODs Zugriff auf das Volume.
Jeder POD hat eine eigene private IP. Diese IPs können jedoch bei einem Neustart des PODs wechseln und sollten nicht für die Bereitstellung von Services genutzt werden.
Node
Auf einem Node (aka Minion) werden die oben erwähnten PODs ausgeführt. Es kann dabei ein virtueller oder physischer Server genutzt werden. Der Node selbst benötigt nicht zwingend öffentliche IPs. Kubernetes besitzt ein von Docker unterschiedliches Netzwerkkonzept, in dem die folgenden Punkte erreicht werden müssen:
- Jeder POD kann mit jedem anderen POD (auch auf anderen Nodes) ohne den Einsatz von NAT kommunizieren.
- Jeder Node kann mit jedem POD (auch auf anderen Nodes) ohne den Einsatz von NAT kommunizieren.
- Die IP-Adresse welche ein POD von sich selbst sieht, ist auch die IP-Adresse welche andere PODs sehen (es existiert also kein Masquerading).
Damit dies erreicht werden kann existieren verschiedene Techniken. Wir haben uns für die flannel Variante entschieden (mit dem ‘host-gw’ Backend).
Labels
Die unterschiedlichen Komponenten von Kubernetes können mit Label versehen werden. Diese bestehen aus Key-Value Paaren. Man kann beispielsweise einem POD ein Label ‘app: nginx’ zuweisen. Das Label dient wiederum anderen Komponenten zur Selektion. Labels verknüpfen also verschiedene Komponenten miteinander.
Services
Da sich die IP Adressen von PODs ständig ändern können, wurde in Kubernetes die Service Komponente eingeführt. Sie stellt sicher, dass ein Service eines PODs (oder eine Gruppe von PODs), unter einer gleichbleibenden IP erreicht werden kann. Die sogenannte Service IP stammt dabei aus einem vorher festgelegten privaten IP Adressbereich (der sich von den POD Adressbereichen unterscheidet).
Um die Verknüpfung zwischen Service und POD herzustellen, bedient man sich der Labels. Ein Service selektiert also anhand der Angabe des Labels, an welche POD er Anfragen weiterreichen soll.
Service IPs sind von Haus aus nur innerhalb des Clusters erreichbar. Dazu wird die Anfrage an eine Service IP via iptables an den ‘kube-proxy’ umgeleitet, welcher auf einem bestimmten Port lauscht. Dieser leitet die Anfragen gemäss der Service Deklaration weiter.
Um Services von extern erreichbar zu machen, bedient man sich des NodePort Typs eines Services. Dazu wird (automatisch) ein Port aus einem vorher zu definierenden Bereich ausgewählt (Default: 30000-32767) und zusammen mit der Haupt-IP des Nodes genutzt. Treffen nun Anfragen auf dieser IP-Port Kombination des Nodes ein (beispielsweise von einem LoadBalancer), so werden diese automatisch via iptables an den ‘kube-proxy’ Daemon geleitet, welcher wiederrum die Anfrage an die PODs weiterreicht. Zu beachten ist dabei, dass alle Nodes des Clusters den selben Port nutzen und die Anfragen automatisch an alle Nodes weitergeleitet werden, welche den entsprechenden POD ausführen. In einem Loadbalancer kann man daher den Request an alle Nodes des Clusters leiten lassen, ohne sich um den wirklichen Ausführungsort des PODs kümmern zu müssen.
Replication Controller
Diese Komponente sorgt dafür, dass PODs immer in einer gewissen Anzahl laufen. Benutzt man keinen Replication Controller für das Starten von PODs, so werden diese in einem Fehlerfall nicht automatisch neu gestartet. Der Replication Controller wird auch dazu genutzt, um Deployments durchzuführen. Dazu wird ein zweiter Replication Controller angelegt, welcher Schrittweise neue PODs startet. Der ursprüngliche Replication Controller fährt dabei schrittweise die Anzahl seiner PODs zurück. Damit ist sichergestellt, dass immer genügend PODs zur Verfügung stehen und es zu keinem Unterbruch kommt.
Volume
Kubernetes unterstützt das persistente Speichern von Daten in PODs. Dazu werden Volumes genutzt, welche in den jeweiligen POD gemountet werden. Es können dabei verschiedene Backends genutzt werden:
- Amazon Elastic Block Store
- nfs
- iscsi
- glusterfs
- rbd (ceph)
- git
Besonders interessant ist dabei glusterfs und NFS, welche den gleichzeitig lesenden und schreibenden Zugriff auf verschiedenen Nodes erlaubt.
Experimente mit einem Testcluster
Mit dem geballten Wissen über die einzelnen Komponenten, setzten wir einen Kubernetes Cluster auf. Dies gestaltete sich recht einfach und schnell. Von einer zentralen Maschine werden über ein Setup Skript alle benötigten Binaries auf den Master Server und die Nodes kopiert. In einem produktiven Betrieb würde es hier sicherlich ein Paket benötigen, aber in einer Testinstallation kann man auf ein Setup Skript zurück greifen. Nachdem der Cluster aufgesetzt ist, können PODs erstellt werden.
Dies kann mit Hilfe von kubectl und YAML Dateien geschehen. Folgendes Beispiel erstellt einen Replication Controller welcher 5 nginx PODs startet:
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx-test-controller
spec:
replicas: 5
selector:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80Man muss im template die POD Definition angeben, welche beim Erstellen des PODs durch den Replication Controller genutzt werden soll. Weiterhin sind die PODs nach dem Start nicht über eine einheitliche IP zu erreichen. Dazu muss zuerst ein ‘Service’ definiert werden:
apiVersion: v1
kind: Service
metadata:
name: nginx-http-service
spec:
ports:
- port: 8000
targetPort: 80
protocol: TCP
nodePort: 30001
selector:
app: nginx
type: NodePortNun werden alle Requests an den Port 30001 auf jedem Node an die entsprechenden PODs weiter geleitet (via RoundRobin). Zusätzlich wird eine Cluster IP erstellt welche auf Port 8000 alle Requests entgegen nimmt und an die PODs weiter leitet. Diese IP ist jedoch nur innerhalb des Clusters erreichbar.
Wir haben auch einmal geschaut wie schnell PODs von einem fehlerhaften Node, auf einen neuen Node transferiert werden. Dies hat mit den Standardeinstellungen mehrere Minuten gedauert. Nachdem wir die Timeouts dann manuell angepasst hatten, funktionierte auch dies etwas schneller. Leider gab es in der getesteten Version noch keine ‘einfache’ Möglichkeit, einen Node in einen ‘Wartungsmodus’ zu versetzen. Hier muss der Status manuell für einen Node gepatched werden.
Das bisher grösste Problem für einen produktiven Einsatz (in einem Multi-Tenant Cluster), besteht aber im Fehlen von Firewall Regeln innerhalb des Clusters. Jeder POD kann die Services von anderen PODs nutzen und erreichen. Es existiert zwar eine Namespace Ressource (siehe dazu hier). Diese kümmert sich jedoch bisher nur um Ressourcen Quotas (CPU, Memory, etc) oder um den Geltungsbereich von Ressourcen Namen im Cluster. Ein entsprechender Firewalling Feature Request besteht jedoch auch schon.
Fazit
Kubernetes ist sehr stark am Wachsen und bietet jetzt schon tolle Möglichkeiten. Die Konzepte gefallen gut, und ein Cluster ist relativ schnell aufgesetzt. Leider kann man bisher noch keine Firewall Einstellungen zwischen den einzelnen PODs treffen, was den Einsatz eines Multi Tenant Clusters leider nicht ermöglicht. Eventuell bringt hier das neue ‘Multi-Home Networking’ Feature von Docker Version 1.9 neuen Input. Wir werden die Entwicklung von Kubernetes auf jeden Fall im Auge behalten.
Sebastian Nickel arbeitet als Senior Linux System Engineer bei nine.ch. Zusammen mit den Kollegen aus dem „Systems“-Team ist er für die ständige Weiterentwicklung unserer Infrastruktur und Managed Services verantwortlich.

