
Bei nine.ch betreiben wir seit 2014 einen Ceph Cluster als Speicher für einen Teil unserer virtuellen Server. Seit der Einführung haben wir sowohl einige positive als leider auch negative Erfahrungen gemacht. Wir möchten diese hier teilen und Ihnen unseren Weg von einem “einfachen” Ceph Storage mit rotierenden Disks zu einem reinen NVMe Cluster näher bringen.
Dies ist der erste Teil der dreiteiligen Serie zu unseren Ceph-Erfahrungen.
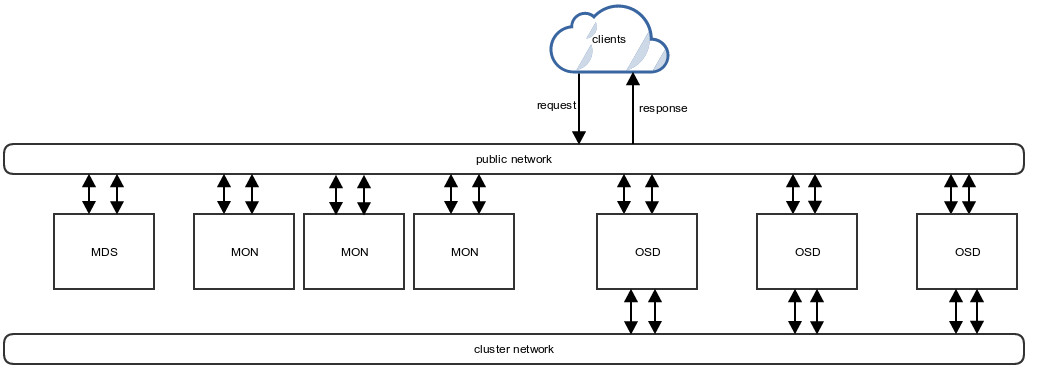
Ceph kurz erklärt
Ceph ist ein verteilter Object Storage, der Daten in Form von Objekten auf mehreren Disks bzw. Servern verteilen kann. Mit diesem kann ein Storage Cluster gebaut werden, welcher in der Grösse unbegrenzt ist.
/ceph-arch.jpg)
Ceph besteht im Grunde aus folgenden Teilen:
MON
Ein MON ist ein Teil von Ceph, der den aktuellen Cluster Zustand kennt und alle beteiligten Cluster Komponenten darüber informiert. Weiterhin überwacht er auch teilweise die OSD-Prozesse.
OSD
… steht für Object Storage Daemon und ist für die Speicherung der einzelnen Objekte auf den physischen Disks (z.B. HDD oder SSD) zuständig.
Journal
Jede OSD benötigt genau ein Journal, welches zuerst die geschriebenen Objekte aufnimmt und so für Recovery-Zwecke verwendet werden kann. Das Journal wird in den meisten Fällen auf eine extra Partition oder eine schnellere Disk geschrieben. Die Schreibgeschwindigkeit des Journals bestimmt auch die maximale Schreibgeschwindigkeit des OSD-Prozesses.
RBD
… ist das RADOS Block Device und kann als Block-Device gemountet werden. Wir verwenden diese als virtuelle Festplatten unserer VServer.
MDS
… ist ein Metadaten-Speicher, welcher für CephFS verwendet wird.
CephFS
Dies ist ein verteiltes Dateisystem, welches auf mehreren Servern eingebunden werden kann. Somit kann es zum Beispiel alternativ für NFS verwendet werden.
Pool
Die sogenannten Pools sind logische Zuordnungseinheiten, in welchen dann beispielsweise verschiedene RBD-Images zusammengefasst werden. Sie dienen dazu, zusammengehörende Objekte nach gleichen Regeln auf die OSDs aufzuteilen. In den Pools kann zum Beispiel festgelegt werden, wie häufig die darin enthaltenen Objekte repliziert werden sollen.
Ausgangslage
Gegen Ende 2015 war unser bestehender Ceph Cluster, welchen wir für virtuelle Server im Colozueri.ch 4.2 einsetzten, in vollem Betrieb und wir entschlossen uns, einen weiteren Storage Cluster im Colozueri.ch 4.1 aufzubauen. Dieser sollte ursprünglich genau gleich wie der bereits vorhandene Cluster aufgebaut werden.
Kurz bevor wir den neuen Cluster für Kundensysteme in Betrieb nehmen wollten, bemerkten wir, dass der alte Ceph Cluster langsam an seine Leistungsgrenzen stiess. Wir entschlossen uns daher, mit dem neuen Cluster noch etwas zu warten, um die Grenzen genauer abschätzen und allfällig nötige Tunings von Anfang beachten zu können.
In der Folge erarbeiteten wir einige Varianten, wie der neue Cluster aufgebaut werden könnte. Es zeigte sich jedoch, dass die Nutzung von HDDs langfristig eine signifikante horizontale Skalierung erfordern würde. Eine andere Variante wäre der Einbau eines sogenannten SSD Caching-Layer gewesen, der Objekte zwischenspeichert und so die Lesegeschwindigkeit ebenfalls erheblich erhöhen sollte (unsere Erfahrungen mit dem Caching sind folgend unter “Caching-Layer” beschrieben). Zusammenfassend mussten wir uns daher nach einer anderen Hardwarezusammenstellung umsehen.
Caching-Layer
Dieser Versuch beinhaltete den Aufbau eines Caching-Layers für Ceph in unserem Staging-Bereich. Hierfür nahmen wir zwei mit SSDs bestückte Server in den Staging-Cluster auf und definierten die Speicherung der Daten eines extra dafür angelegten Pools auf diesen SSDs.
Bei der Aktivierung dieser zusätzlichen Ebene für das Caching der benötigten Daten traten, solange der Cache “kalt” (also ohne Daten) war, zunächst Probleme auf. In den ersten Minuten lief die Lese- und Schreibgeschwindigkeit gegen 0 bis der Cache die benötigten Daten vorrätig hatte. Als der Cache-Layer dann “warm” war, stieg die Performance bei unseren Tests um etwa das Dreifache an.
Unsere Vorteile, die uns der Caching-Layer verdeutlichte:
- Erheblich verbesserte Performance
- Transparentes De-/Aktivieren
Die Nachteile allerdings überwogen bei diesem Vergleich:
- Auftretende Probleme, solange der Cache “kalt” ist
- Ein Caching-Layer ist für den Betrieb mit völlig unterschiedlichen VMs nicht gut geeignet, da nicht viele Daten wirklich gecachet werden können
- Beim Ausfall einer Disk des Caches bricht die Performance für längere Zeit komplett ein
- Für die unterschiedlichen Daten wäre ein riesiger Caching-Pool (also viele SSDs) nötig gewesen
- Bei einem eventuellen Reboot aller vorhandenen Server (z.B. aufgrund eines Kernel-Upgrades) wird der Cache beim Booten der Instanzen mit zu vielen Daten befüllt, die im späteren Verlauf nicht mehr benötigt werden. Es kommt dann zu sogenannten “Cache Evictions”, welche man vermeiden sollte.
Daher entschieden wir uns gegen diese Lösung.
Benchmarks der “alten” Systeme
Um genauer definieren zu können, wie die Performance unseres neuen Ceph-Storage-Clusters aussehen sollte, begannen wir, alle Teile der bestehenden beiden Cluster zu messen. So entstand innerhalb kurzer Zeit eine umfangreiche Sammlung von Geschwindigkeitstests des alten und des bereits aufgebauten neuen Clusters im Colozueri.ch 4.1. Des Weiteren wurden grobe Kennzahlen der Leistungen virtueller Maschinen von anderen Anbietern in diesem Bereich erhoben. Zusätzlich analysierten wir die Performance des lokalen Speichers unserer virtuellen Server.
Somit konnten wir unser sehr hoch gesetztes Ziel definieren: Unser neuer Cluster musste sicher schneller sein, als die bestehenden Storage-Varianten.
Suche nach der Lösung
Zur Erreichung dieses Ziels mussten wir zuerst Informationen zusammentragen, wie der “perfekte” Ceph-Cluster aussehen sollte. Daher besuchten wir diverse Schulungen und stellten den Kontakt zu verschiedenen Stellen her, die uns in dieser Frage unterstützen konnten. Leider gab es, wie erwartet, keine allgemein gültige Patentlösung.
Daher planten wir unseren Cluster selbst weiter und statteten diesen komplett mit “normalen” SSDs aus. Dieser Umstand erhöhte natürlich den Anschaffungspreis des Clusters im gleichen Masse wie dessen Performance. Auf Basis verschiedener Dokumentationen, die wir zur Eruierung nutzten, stiessen wir unter anderem auch auf NVMe Disks. Eine dieser Dokumentationen war der Red Hat Ceph Storage Hardware Configuration Guide.
So entwickelten wir vier verschiedene Lösungen:
- 12 Nodes mit je 12x SATA und 2x SSD als Journal
- 4 Nodes mit je 24x SSD
- 6 Nodes mit je 4x SSD und 1x NVMe als Journal
- 6 Nodes mit je 4x NVMe
Nach der Prüfung der einzelnen Varianten auf ihre Leistungsfähigkeit und Wirtschaftlichkeit erhielten wir folgendes Ergebnis:
- Variante 1 bot den günstigsten Speicherplatz pro GB, allerdings auch mit Abstand die schlechteste Performance
- Varianten 2 - 4 unterschieden sich nicht wesentlich im Preis pro GB
Wir entschieden uns für die Umsetzung eines NVMe Clusters, um unseren Kunden die leistungsfähigste Variante bieten zu können.
Im nächsten Beitrag der Serie zu unseren Erfahrungen mit Ceph erläutern wir den Zusammenbau des eigentlichen Clusters sowie die ersten Benchmarks und Tunings.

