At nine.ch, since 2014 we have operated a Ceph Cluster as storage for a part of our virtual servers. Since its introduction we have had both positive and, unfortunately, negative experiences. We would like to share these here and tell you a little more about our journey from a “simple” Ceph Storage with rotating discs to a purely NVMe cluster.
This is the first part of a three-part series on our Ceph experiences.
Ceph explained in brief
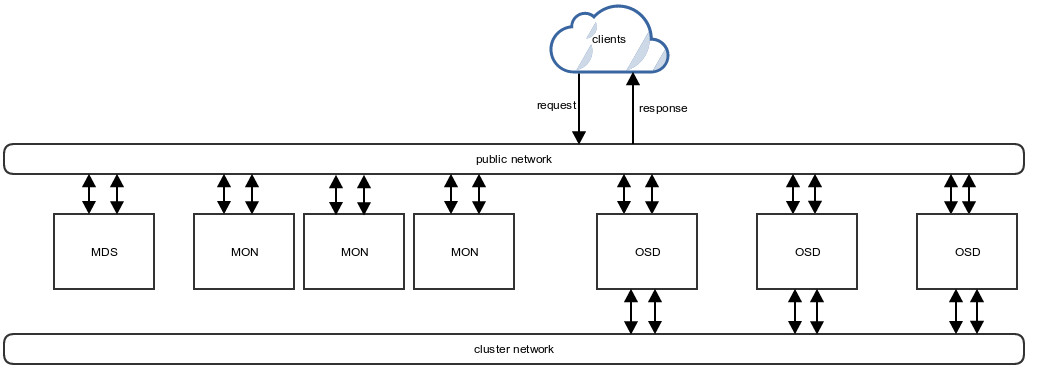
Ceph is a distributed object storage system which can distribute data in the form of objects across several discs or servers. This allows a storage cluster to be built which has no size limit.
/ceph-arch.jpg)
Ceph consists primarily of the following parts:
MON
A MON is a part of Ceph which knows the current cluster situation and informs all cluster parts involved about it. In addition, it also partially monitors the OSD processes.
OSD
… stands for Object Storage Daemon and is responsible for saving the individual objects on the physical discs (e.g. HDD or SSD).
Journal
Every OSD needs a journal, which initially records the written objects and can therefore be used for recovery purposes. In most cases, the journal is written on an extra partition or a faster disc. The writing speed of the journal also defines the maximum writing speed of the OSD process.
RBD
… is the RADOS Block Device and can be mounted as a block device. We use these as virtual hard drives for our servers.
MDS
… is a meta-data store which is used for CephFS.
CephFS
This is a distributed data store which can be connected to multiple servers. This means that it can be used as an alternative to NFS, for example.
Pool
The so-called pools are logical allocation units in which, for example, different RBD images may be condensed. They also serve the purpose of dividing objects that belong together according to the same rules on the OSDs. In the pools you can determine, for example, how often the objects contained within them should be replicated.
Initial situation
Towards the end of 2015, our existing Ceph cluster, which we used for virtual servers in Colozueri.ch 4.2, was in full operation and we decided to establish another storage cluster in Colozueri.ch 4.1. Originally, this was meant to be exactly the same as the cluster we already had.
Shortly before we wanted to put the new cluster into operation for customer systems, we noticed that the old Ceph cluster was slowly reaching its performance limits. We therefore decided to wait a little with the new cluster in order to assess the limits more accurately and detect any necessary tunings early on.
Following this, we worked out a few variations on how the new cluster could be set up. It became clear, however, that the use of HDDs in the long term would require significant horizontal scaling. Another option would have been the integration of a so-called SSD caching layer, which caches objects and should therefore also significantly increase the reading speed (our experiences with caching are described below under “Caching layer”). So in the end we had to look around for another hardware configuration.
Caching layer
This attempt included the establishment of a caching layer for Ceph in our staging area. To this end, we included two servers with SSDs in the staging cluster and defined the storage of the data of a specially created pool on these SSDs.
With the activation of this extra level for caching the necessary data, some problems initially occurred when the cache was “cold” (without data). In the first few minutes, the reading and writing speed ran at about 0 until the cache had the data loaded. When the cache layer was then “warm”, the performance in our tests improved around threefold.
The benefits for us made clear by the caching layer:
- Considerably improved performance
- Transparent activation and deactivation
These were, however, outweighed by the disadvantages:
- Problems arising when the cache is “cold”
- A caching layer is not well suited to operation with completely different VMs, as not much data can really be cached
- If one disc of the cache fails, the performance is completely disrupted for a long time
- A huge caching pool (lots of SSDs) would be required for the different data
- In the case of a possible reboot of all servers (e.g. due to a core update), when booting the entities the cache is filled with too much data, which is no longer needed later on. This then leads to “cache evictions”, which are generally to be avoided.
Therefore, we decided against this solution.
Benchmarks of the “old” system
In order to be able to define more precisely what the performance of our new Ceph storage cluster should look like, we began measuring all parts of the two existing clusters. This meant that within a short amount of time a comprehensive set of speed tests was created for the old cluster and the new, recently established cluster in Colozueri.ch 4.1. Furthermore, rough key figures of the performance of virtual machines from other providers in this area were collected. In addition, we analysed the performance of the local storage of our virtual server.
This meant that we were able to define our ambitious goal: our new cluster definitely needed to be quicker than the existing storage variants.
Search for the perfect solution
In order to achieve this goal, we first needed to gather together information on what the “perfect” Ceph cluster would look like. To this end, we took part in range of training sessions and got in touch with various contacts who could support us in answering this question. Unfortunately, as expected there was no all-round patent solution available.
Therefore we continued to plan our cluster ourselves and equipped this completely with “normal” SSDs. This of course increased the acquisition price of the cluster, analogous with the increase in performance. Based on various documentation that we used for research, we came across, amongst other things, NVMe discs. One of these pieces of documentation was the Red Hat Ceph Storage Hardware Configuration Guide.
We then went on to develop four different solutions:
- 12 nodes each with 12x SATA and 2x SSD as journal
- 4 nodes each with 24x SSD
- 6 nodes each with 4x SSD and 1x NVMe as journal
- 6 nodes each with 4x NVMe
After checking the individual variants for performance capability and economic efficiency, we obtained the following results:
- Variant 1 offered the cheapest storage space per GB, but also had markedly the worst performance
- Variants 2-4 did not vary greatly in price per GB
We decided to implement an NVMe cluster in order to be able to offer our customers the variant with the highest performance capability.
In the next instalment of the series on our experiences with Ceph, we will describe the assembly of the actual cluster and the first benchmarks and tunings.