



































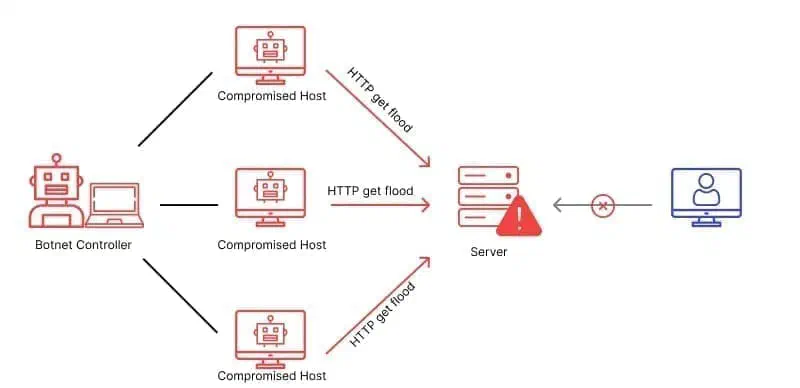






























As more developers get familiar with deploying to Kubernetes, the need for better isolation between tenants becomes more important. Is it enough to just have access to a namespace in a cluster? I would argue for most use-cases to deploy your production apps, yes.
As more developers get familiar with deploying to Kubernetes, the need for better isolation between tenants becomes more important. Is it enough to just have access to a namespace in a cluster? I would argue for most use-cases to deploy your production apps, yes. But if you want dynamic test environments or to schedule your GitLab builds on a certain set of nodes, it can quickly get quite complex to safely set this up on the same cluster as your production apps. Using a full seperate cluster for that is possible but it’s slow to setup and it’s usually quite expensive if you use a fully managed cluster.
The Kubernetes multi-tenancy SIG (Special Interest Group) has been prototyping a virtual cluster implementation for quite some time, but it has always stayed somewhat experimental and limited. The vcluster project attempts to address these shortcomings, implementing a similar architecture but with a rich set of features, even in the earliest implementation, and has really good documentation.
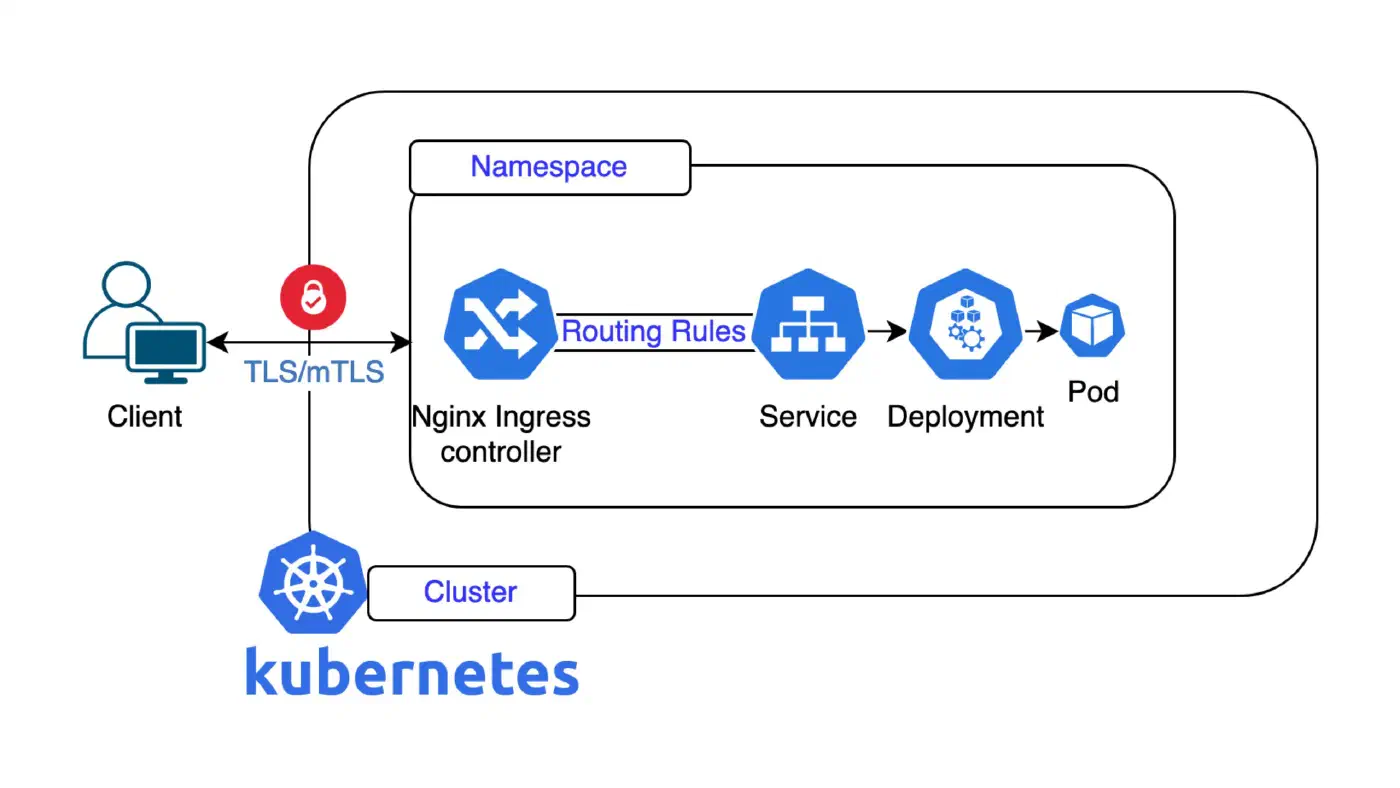
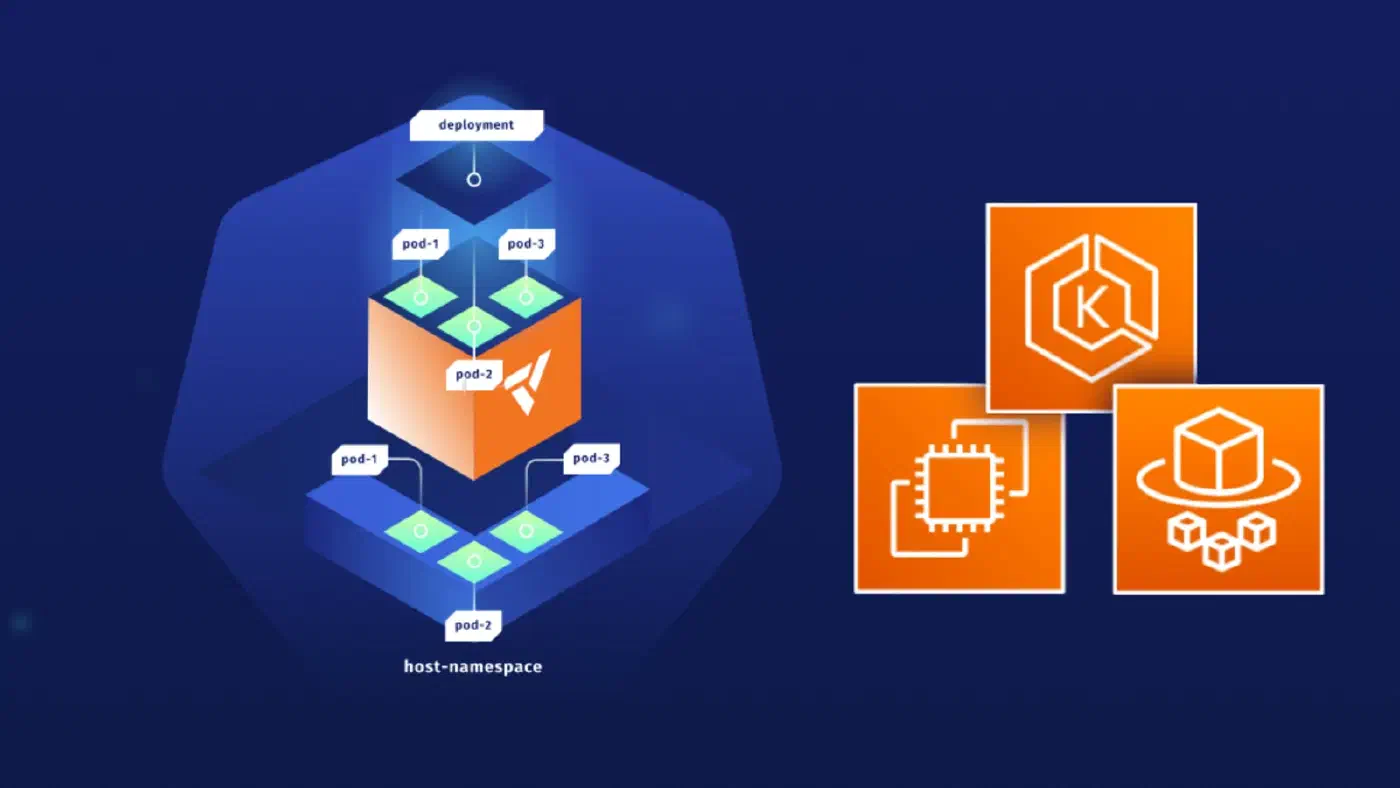
The basic concept of a vcluster is that it starts up a kube-apiserver inside a pod on the host cluster and then a syncer component will ensure that certain resources are synced between the vcluster and the host cluster so existing infrastructure and services on the host cluster can be reused. For example, if you request a storage volume (PVC) on the vcluster, it will be synced to the host cluster where the existing storage implementation will take care of creating the actual volume, without the need to install any complicated CSI drivers on your vcluster. You just get dynamic volume provisioning “for free”. This also applies to things like load balancers, ingresses etc. Your workloads (pods) created on the vcluster can also make use of existing nodes on the host cluster. But there is also the option to further isolate workloads by scheduling all workloads created inside the vcluster on dedicated nodes of the host cluster. This is also how vclusters are implemented at Nine, you don’t need to worry about sharing a node with other tenants
Source vcluster: vcluster.com
When to use a vcluster
That’s of course completely up to you but here are some use-cases we could think of:
CI/CD: Because of the fast creation and deletion times of a vcluster, as well as their low cost, they lend themselves to be used in CI/CD pipelines to test deployments of your apps end-to-end.
Testing new Kubernetes API versions: We try to always provide the latest Kubernetes releases within vcluster so you can test your apps against new API versions early.
Well isolated and cost effective environments: Staging and development environments can use their own vcluster to be better isolated from production instead of using multiple namespaces on a single NKE cluster.
Test new CRD versions and operators: Testing new CRDs and/or operators can easily be tested on a temporary vcluster. Want to try an upgrade of cert-manager and see if your certificates are still getting signed? A vcluster can help with that.
How we are making use of vclusters
At Nine we are constantly looking at new software to solve certain problems , which means we often need to deploy something on a Kubernetes cluster and tear it down again after we are done with testing. In the past we have been using local clusters with kind or Minikube but with a lot of software you have to resort to workarounds to get it running, e.g. find the usually hidden “allow insecure TLS” flag as it’s not really simple to get a trusted TLS certificate inside your temporary kind cluster. Or say you want to share your prototype with other team members, it gets quite tricky to expose your locally running applications to the internet. Here a vcluster offers the best of both worlds as you can get an (almost) full cluster within seconds.
Another use-case of ours is running the staging environment for our API and controllers. We make heavy use of CRDs, which makes it hard to use a shared cluster but as we are just running a few pods for the controllers a full cluster would also be wasteful.
Comparison to NKE
We see vclusters as a complimentary tool to our fully managed NKE clusters. The API server of a vcluster does not have the same reliability as a complete Kubernetes cluster such as NKE. However, a brief failure of the API server does not usually cause your application to fail. This comparison table should give an overview of most of the differences:
| NKE | vcluster | |
|---|---|---|
| Service Type Load Balancer | ✓ | ✓ |
| Persistent Storage (RWO) | ✓ | ✓ |
| Ingress | ✓ | ✓ |
| Autoscaling | ✓ | ✓ |
| Argo CD Integration | ✓ | ✓ |
| NKE Maschinentypen | ✓ | ✓ |
| Dedizierte Worker Nodes | ✓ | ✓ |
| Dedizierte HA Control-Plane Nodes | ✓ | ✗ |
| Cluster Add-ons | ✓ | ✗ |
| Automatisches Backup | ✓ | ✗ |
| Verfügbarkeitsgarantie (SLA) | ✓ | ✗ |
| Cluster-Gebühr | ✓ | ✗ |
| Schnelle Erstellungszeit (<~2 min) | ✗ | ✓ |
| Cluster Admin | ✗ | ✓ |
Getting started
While vclusters can be created in Cockpit](https://nine.ch/en/blog/vcluster#comparison-to-nke), we have also added it to our CLI utility to offer a kind-like experience and to support CI/CD workflows. You can create a new vcluster with just a single command.
$ nctl create vcluster
✓ created vcluster "grown-velocity"
✓ waiting for vcluster to be ready ⏳
✓ vcluster ready 🐧
✓ added grown-velocity/nine to kubeconfig 📋
✓ logged into cluster grown-velocity/nine 🚀
$ nctl get clusters
NAME NAMESPACE PROVIDER NUM_NODES
grown-velocity nine vcluster 1
S
By default this will choose a random name for your vcluster and spawn a single node that is dedicated to this vcluster. All of this can be configured using flags, use nctl create vcluster -h to get an overview over all available flags.
Now you can start to use the vcluster just like any Kubernetes cluster.
$ kubectl get ns
NAME STATUS AGE
kube-system Active 47s
kube-public Active 47s
kube-node-lease Active 47s
default Active 47s
$ nctl delete vcluster grown-velocity
do you really want to delete the vcluster "grown-velocity/nine"? [y|n]: y
✓ vcluster deletion started
✓ vcluster deleted 🗑
Do you have any questions?
