After many successful years of operation, at last we decided to do something about our aging VM management software and its underlying server hardware. The custom built software solution - once the pride of the nine engineers - was falling behind what is required to offer competitive VM based managed services to our customers. Additionally components like hard disks were starting to show serious signs of age. You can read more about this in a separate blog post.
After careful consideration we chose Nutanix as our in house infrastructure instead of moving our VM's in the public cloud. Everything looked promising, but we were soon faced with a tough software development challenge. Beyond the challenging task to replace the custom built software with a Terraform and a GitOps based workflow, we also had the challenging task of finding a way that Puppet, our automation software, could gather all It’s required information within this new ecosystem.
When Puppet sets up a client’s managed service and the supporting tech stack, for example monitoring, it needs to know which client the service belongs to as well as a few other important parameters. In the past, this was solved by running a Cron job triggering a script that wrote a static file into the filesystem of the VM. This was working acceptably and the same concept was even extended to support AWS based instances.
There were however strong objections to doing this again for the Nutanix based VM’s:
- We would need to extend and refactor old legacy code where we simply had no idea how it worked, code written in a language that we no longer used for our new software projects.
- We would need to access the Nutanix API from the existing code - creating a direct dependency between what we consider as legacy code and the shiny new Nutanix appliance.
- The Cron ran periodically, which introduced a delay when an engineer made a change.
We had a few ideas on how to solve this problem without touching the existing solution, for example using cloud-init or a direct connection from Puppet to the Nutanix appliance via API - however, all of them were ruled out due to serious downsides. After further deliberation, as well as a few sketches on the whiteboard we came up with Meko (metadata Kollektor -German for the collector).
Meko- an API and CLI tool which provides the same information as the Cron job but in a future proof way:
- It uses a standard Rest API with puppet hosts authentication.
- It allows us to query the information from the command line.
- It is modular, allowing us to add or modify the data sources of the metadata independent from Puppet.
- The credentials for accessing external metadata sources are stored in a single place and not located on customer VMs.
- It is written in GO.
- Puppet is in control - It can request the data when it needs it and does not depend on a remote job to run.
- It provides an endpoint that allows us to monitor key performance metrics and service status of the API.
It also makes use of caching so it will also work if the provider can not provide any data.
Meko is currently configured to provide metadata from 3 backends:
- Stats: A custom built Inventory Software
- Nvirt: Our current VM provisioning system
- Nutanix: Our new VM solution
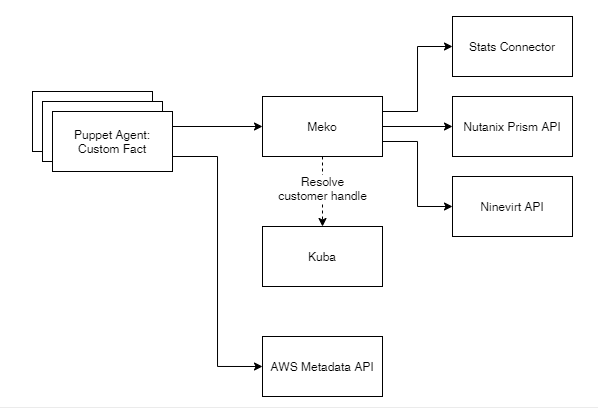
Meko is used by Facter which is built into Puppet and allows the use of external data inside Puppet. We already use Facter to load file based data, so we only had to configure it to communicate to the REST API using HTTPS. Puppet knows which infrastructure it runs on so it was easy to keep the detection part in Facter and to tell MEKO which backend to use to resolve the data.
Detection snippet:

Meko and the required Puppet changes were rolled out into production without any issues:
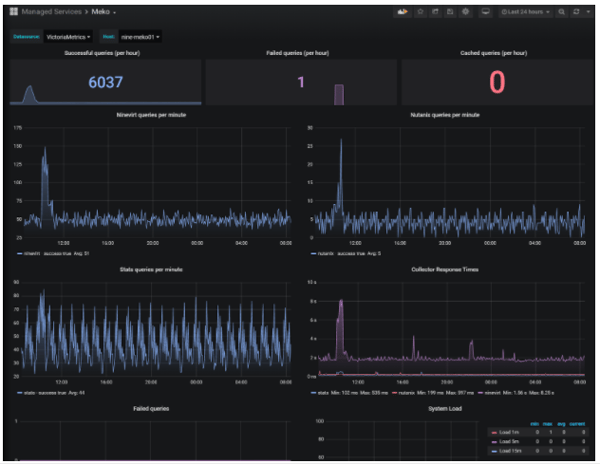
We are very satisfied that this worked out so well. We look forward to rolling out Nutanix into our second Datacenter, as well as it’s used for our unmanaged servers solution.
Never miss an update again!