

Nach vielen erfolgreichen Betriebsjahren haben wir beschlossen, unsere in die Jahre gekommene VM-Verwaltungssoftware und die ihr zugrunde liegende Server-Hardware zu ersetzen. Die massgeschneiderte Softwarelösung - einst der Stolz der nine Ingenieure - bietet nicht mehr die erforderlichen Funktionen um unseren Kunden wettbewerbsfähige, VM-basierte Managed Services anzubieten. Komponenten wie Festplatten beginnen ernsthafte Alterserscheinungen zu zeigen. Mehr dazu in einem separaten Blog-Beitrag.
Anstatt in die Public Cloud zu investieren haben wir uns nach reiflicher Überlegung entschieden, Nutanix als Ersatz für unsere Infrastruktur zu verwenden. Alles sah vielversprechend aus, aber dann wurden wir mit einer grossen Herausforderung in der Software Entwicklung konfrontiert. Neben der herausfordernden Aufgabe, die kundenspezifische Software mit Terraform und einem GitOps-basierten Workflow zu ersetzen, mussten wir einen Weg finden wie Puppet, unsere Automatisierungssoftware, alle erforderlichen Informationen innerhalb dieser neuen Umgebung bekommt.
Wenn Puppet den Managed Service eines Kunden und den unterstützenden Tech-Stack, wie z.B. Monitoring Services, einrichtet. muss es wissen, zu welchem Kunden der Dienst gehört. Aktuell wird dies so gelöst, dass per Cron-Job periodisch ein Skript ausgeführt wird. Dieses schreibt eine Datei mit der Kundeninformation und anderen Metadaten in das Dateisystem der VM. Dies funktionierte akzeptabel und das gleiche Konzept wurde sogar auf die Unterstützung von AWS-basierten Instanzen ausgeweitet.
Es gab jedoch starke Einwände dagegen, dies für die Nutanix-basierten VMs erneut zu tun:
- Wir müssten alten Legacy-Code, bei dem wir einfach keine Ahnung hatten, wie er funktionierte, erweitern und überarbeiten. Dieser ist ausserdem in einer Sprache geschrieben, die wir für unsere neuen Software-Projekte nicht mehr verwendeten.
- Wir müssten vom bestehenden Code aus auf die Nutanix API zugreifen. Das würde eine direkte Abhängigkeit zwischen Legacy-Code und der neuen Nutanix Appliance schaffen.
- Der Cron bleibt bestehen. Es gibt weiterhin eine unnötige Verzögerung wenn ein Ingenieur eine Änderung macht.
Wir hatten ein paar Ideen, wie wir dieses Problem lösen könnten, ohne die bestehende Lösung zu verwenden, z.B. mittels Cloud-init oder einer direkten Verbindung von Puppet zur Nutanix-Appliance via API - alle wurden jedoch aufgrund gravierender Nachteile ausgeschlossen. Nach weiteren Überlegungen, sowie einigen Skizzen am Whiteboard, entstand MEKO (Metadaten-Kollektor).
Meko ein API- und CLI-Tool, welches die gleichen Informationen wie der Cronjob liefert, aber zukunftssicher ist:
- Es verwendet eine Standard-Rest-API mit Puppet-Host-Authentifizierung.
- Das Tool kann auch in der Kommandozeile verwendet werden
- Es ist modular aufgebaut und erlaubt es uns, die Datenquellen der Metadaten unabhängig von Puppet hinzuzufügen oder zu ändern.
- Die Zugangsdaten für den Zugriff auf externe Metadaten Quellen werden an einem einzigen Ort gespeichert und befinden sich nicht auf Kunden-VMs.
- Es ist in GO geschrieben.
- Puppet hat die Kontrolle - Es kann die Daten anfordern, wenn es sie braucht, und ist nicht von der Ausführung eines Remote-Jobs abhängig.
- Es bietet einen Endpunkt, der es uns ermöglicht, wichtige Leistungsmetriken und den Servicestatus der API zu überwachen.
Meko nutzt Caching für eine bessere Performance und funktioniert auch dann, wenn der Provider keine Daten zur Verfügung stellen kann.
Meko ist derzeit so konfiguriert, dass es Metadaten von 3 Backends zur Verfügung stellt:
- Stats: Eine kundenspezifische Inventarisierungssoftware
- Nvirt: Unser aktuelles VM Management System
- Nutanix: Unsere neue VM-Lösung
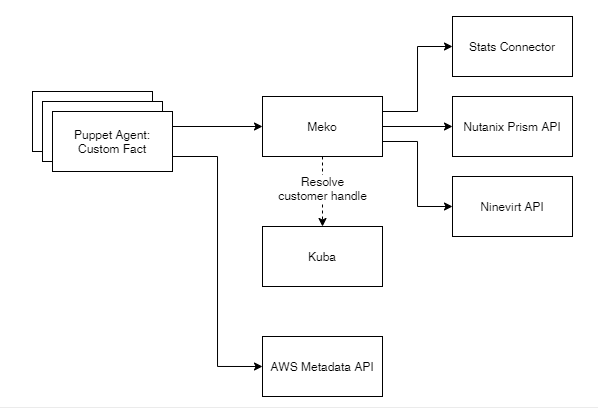
Meko wird von Facter verwendet, welches in Puppet eingebaut ist und die Verwendung von externen Daten innerhalb von Puppet erlaubt. Wir verwenden Facter bereits zum Laden dateibasierter Daten, so dass wir es nur noch für die Kommunikation mit der REST-API über HTTPS konfigurieren mussten. Da Puppet weiss, auf welcher Infrastruktur es läuft, war es einfach, den Erkennungsteil in Facter zu belassen und dann MEKO mitzuteilen, welches Backend zur Auflösung der Daten verwendet werden soll.
Detection snippet:

Mekound die erforderlichen Änderungen an Puppet wurden ohne Probleme in die Produktivumgebung überführt.
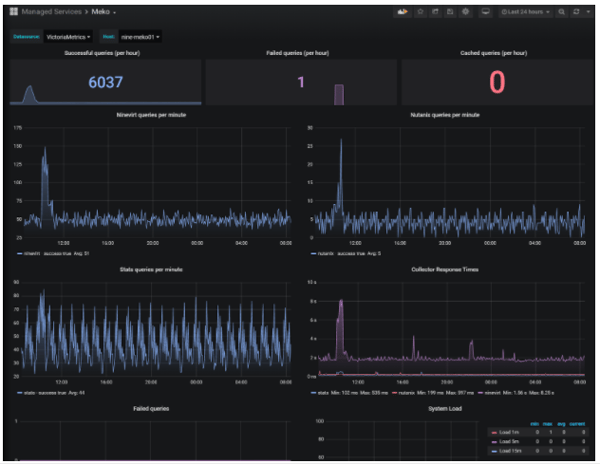
Wir sind sehr zufrieden, dass dies so gut geklappt hat und freuen uns nun auf die baldige Einführung von Nutanix in unserem zweiten Rechenzentrum.
Nie mehr ein Update verpassen!


